March Update: Everything is a subscription, Flow shadows, Canvas map pulling

Quick March development round up on some of the bigger, "demoable" things. I'm running slightly behind my planned release schedule, but I think it will be worth it - much more was accomplished than I had in my roadmap when I made the January video.
Hope to pull it all together and release as soon as I can.
Flow shadows (history)
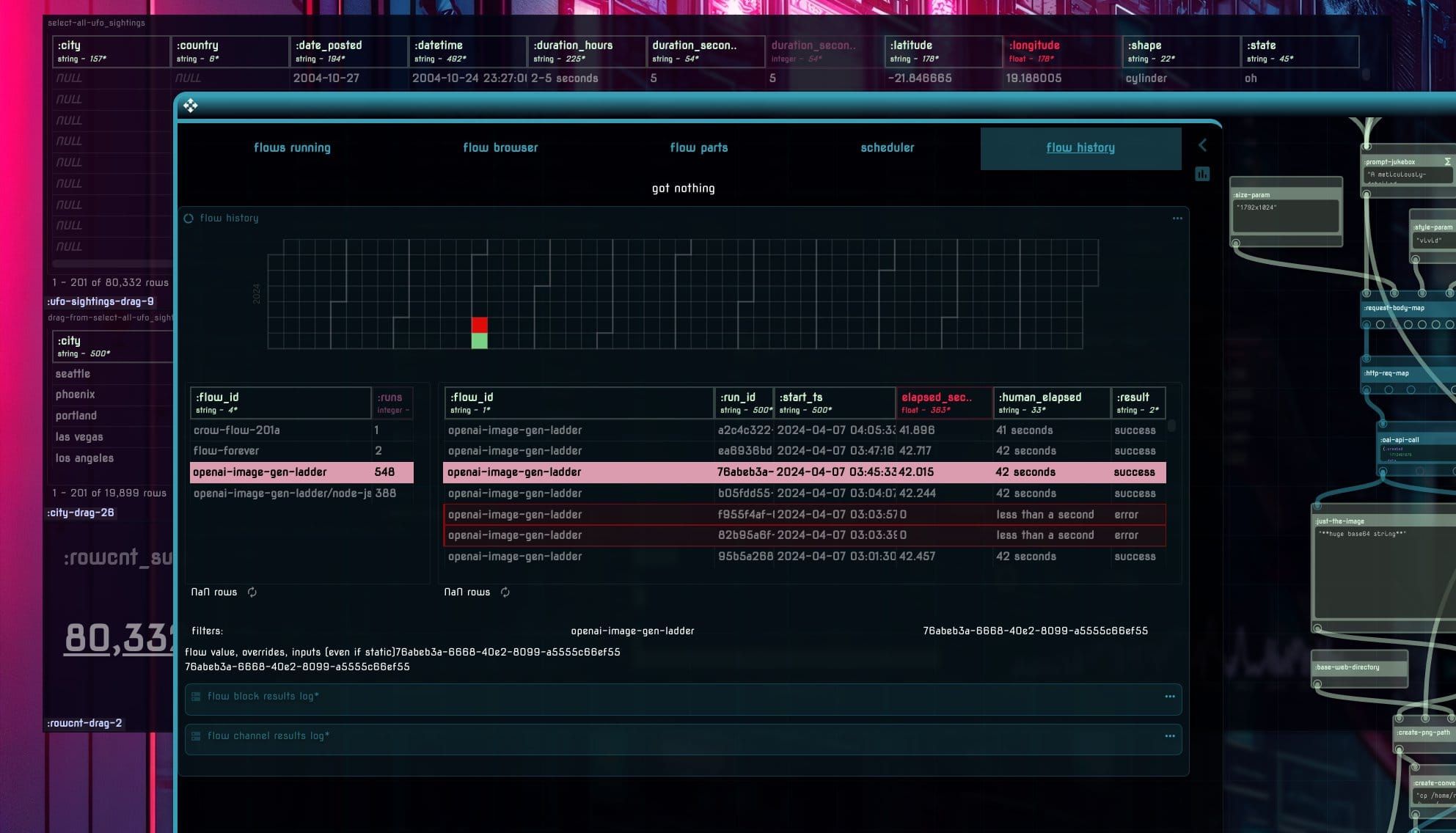
Flows are great. Some are ephemeral, but many are not - we need a non-painful way to find out what happened - esp if there was an error or something went awry. It's pretty much what you'd expect it to be - an image of the flow as it ran with its inputs and outputs - but with a twist.
The historic flow run can be browsed via the actual flow builder UI - there you can examine the final state, run it again (with the historical materialized inputs), or fork that particular version into another.
Feels way cooler than it sounds.
Flow shadows. Browse old runs, including their as-was "source" (useful for revisions, forking). For dynamic flows with RESTed or reactive inputs from clients - all the used values are materialized in the shadow state. You can even re-run it "as it was"... pic.twitter.com/qTd4mnT4ez
— Ryan Robitaille (@ryrobes) April 8, 2024
Only thing left to round out the suite of features for "version zero" of integrated flows is proper scheduling - but more on that later.
Subscriptions
(an extension of "Everything is a Parameter")
You've probably heard me go on about "everything" being a parameter - and I truly think that is an important part of being able to make highly reactive and interactive data boards - but we can take that one step further by making params into (server side) "subscriptions" as well.
Think of it this way - if a param is a piece of data in your workspace, you own it, you care for it - a subscription is just a param that lives somewhere else. A param that is not yours, but you may want to borrow without having to feed and clothe it.
Sounds reasonable to me!
This way you can not only reference any flow values (and be pushed the new values when they happen), but also views and queries on saved boards (a reference to them, not a copied fork), as well as queries, views, and parameters on OTHER people's clients and sessions (even dead ones). Why other clients? Why not. It just goes to show the flexibility of this reactive data parameter ecosystem.
This can be great for traditional dashboard scenarios where you want to reference a query or a view - but ensure that any upstream changes also make it to your version as soon as they happen.
More RVBBIT stuff today. Things I wish other tools cared about.
— Ryan Robitaille (@ryrobes) March 24, 2024
*Everything* can be a parameter. Flow Values, blocks, views, queries, client params, render objects, other dashboard parts, etc. Example using 2 clients...
Data is data. pic.twitter.com/sD2NCfUQjb
Queries as parameters (with parameters) across live clients. OR everything is a parameter AND a subscription.
— Ryan Robitaille (@ryrobes) March 30, 2024
Clearly I was dropped on my head as a child, but I still think this is pretty wild. pic.twitter.com/8MGMvNTqyN
"Subscribe" to a query on an existing board - build off it. Source query changes (saved to disk, in this case) - all changes push downstream to you ASAP.
— Ryan Robitaille (@ryrobes) April 3, 2024
A "living DB view". Shared dashboard objects, for real. pic.twitter.com/zVNhllcfA4
Earlier I mentioned flow scheduling - the cool thing is, when you have a system of universal reactive pieces of data - your "scheduler" starts looking a lot less like a cron job and way more like a set of IFTTT rules.
i.e. "Run this flow with THIS value, when it's tuesday, every time X happens, BUT only after the partition for table Z has landed, and only if metric Q > 500."
"Run this flow to generate the TPS reports when Bob logs in, and send it directly to his client, and play CartmanHey.wav for him."
"On Monday at 9am do X".
After all, dates and times are just another set of reactive parameters to run logic against. Will be showing this off in a future post.
Canvas map pulling
This is just a fun one, last month I mentioned flow map pulling where you were able to visually pick apart a nested structure of JSON or what-have-you and more easily get to the actual data you need. This is similar to the function on the data canvas - except instead of being hard-coded UI, it's implemented as a rabbit-code (name TBD, basically the shared data and view DSL) function just like you would call :vega-lite or :div or :h-box... simply :data-browser.
Drag out and get a reference that pulls data from the keypath you specified.
Have this for flow building, wanted it for the data canvas as well.
— Ryan Robitaille (@ryrobes) March 15, 2024
Got a nested data structure from a view or a database row? Pull it apart to get the values you want to present.
Also: no "magic", generates easy to grok hiccup style view shortcode. [:get-in :data/field.row… pic.twitter.com/aCsCsikSLX